

- 1. Introduction
- 2. Exclaimer
- 3. Understanding Sound and Sound Waves
- 4. How humans process sound waves
- 5. How Digital Audio Works
- 6. The Role of a Sound Card / Audio Interface
- 7. The Linux Audio Stack
- 7.1. ALSA (Advanced Linux Sound Architecture)
- 7.2. JACK
- 7.3. PulseAudio
- 7.4. PipeWire
- 7.5. So what is it a sound server does?
- 7.6. Which sound server is better for me?
Introduction
Digital audio processing is a complex yet fascinating subject. Getting a deeper understanding requires knowledge in multiple technical disciplines, including physics, electrical/electronical engineering, and some software engineering when it comes to parts of the Linux ecosystem. This article aims to demystify the Linux audio stack by explaining the basics of sound, how humans perceive sound, and the workings of digital audio. We will then dive into the components that make up the Linux audio stack and explore how these interact. Buckle up; it’s going to be a long and informative read.
Exclaimer
In this article, I will simplify concepts and ideas to provide you with the basic knowledge needed to follow along. Each chapter could easily be expanded into a dedicated, lengthy blog post. However, for simplicity’s sake, I have refrained from doing so. If you would like further details about a specific chapter, please feel free to contact me or leave a comment in the comment section below. I’ll be happy to go into more detail if needed/wanted.
Understanding Sound and Sound Waves
Before deep-diving the technicalities of audio processing on Linux, it’s essential to understand what sound is. In a nutshell, sound is a vibration that propagates as an acoustic wave through a medium such as air. These waves are created by vibrating objects (such as speakers, headphones, piezo buzzers, etc.), causing fluctuations in air pressure that our ears can pick up and perceive as sound. Audio waves can have many shapes, the most common waveform is the sine wave. It is the fundamental building block for all other waves existing, and thus it’s important to learn about the sine wave first.

All waveforms have 2 fundamental key properties:
Period (duration): The time it takes the wave to perform a single oscillation.Amplitude: This represents the wave’s strength or intensity, which we perceive as volume. Higher amplitudes generally correspond to louder sounds.
We can derive the Frequency from the period duration of a wave form. The frequency is measured in Hertz (Hz), and it represents the number of oscillations (waves) per second. Higher frequencies correspond to higher-pitched sounds. In other words, the shorter the period duration, the higher the pitch. The higher the frequency the higher the pitch. Thus, the frequency is the inverse of the period duration, or in mathematical terms:
f = 1 / (period duration[s]) = (period duration[s])⁻¹.
Amplitudes can be measured as the pressure variation in the air - the so called Sound Pressure Level (abbreviated as SPL). The standard unit for pressure is Pascal (Pa). In the context of audio, we often deal with very small pressures, so micropascals (µPa) are typically used. However, the most common way of describing amplitude is Decibels (dB). Decibels are a logarithmic unit used to describe the ratio of a particular sound level to a given reference level. Decibels are the preferred unit, because the human ear perceives sound pressure levels logarithmically.
dB SPL: Sound pressure level in decibels. In air, the reference pressure is typically 20 µPa (typically referred to asP0), the threshold of human hearing. It is calculated using the formulaSPL = 20 * log₁₀(P/P0), wherePis the measured pressure andP0 is the reference pressure (20 µPa).dBVanddBu: When sound is converted into an electrical signal by a microphone, the amplitude can be measured in volts (V). This is common in audio equipment and recording.dBVanddBUare units for voltage measurements in audio systems, referencing 1 volt for dBV or 0.775 volts for dBu. Similarily todb SPL,dbV and dBucan be calculated using the same formula, just exchange the reference pressure with a reference voltage. dBV = 20 * log₁₀(V/V0), whereVis the measured voltage andV0` is the reference voltage.
You might wonder how a sine wave actually sounds like? Here’s an example of a sine wave at a frequency of 440 Hz. Please check your volume before you play!
How humans process sound waves
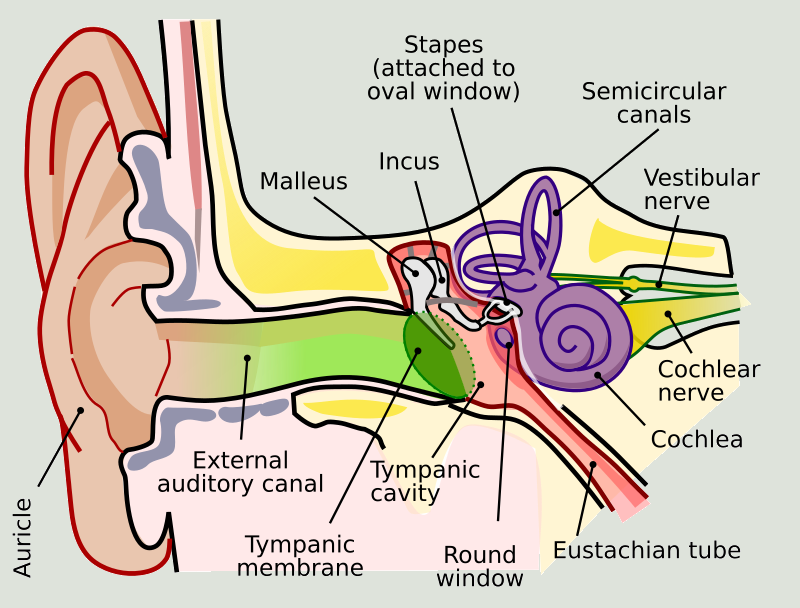
Sound waves are captured by the pinna, the visible part of the outer ear. The pinna helps direct sound waves into the ear canal. The sound waves travel through the ear canal and reach the eardrum (tympanic membrane). The sound waves cause the eardrum to vibrate (very similar to sound waves bring microphone membranes to vibrate). These vibrations correspond to the frequency and amplitude of the incoming sound waves. The vibrations from the eardrum are transmitted to the three tiny bones in the middle ear, known as the ossicles (malleus, incus, and stapes). The ossicles amplify the vibrations and transmit them to the oval window, a membrane-covered opening to the inner ear. The vibrations pass through the oval window and enter the cochlea, a spiral-shaped, fluid-filled structure in the inner ear. Inside the cochlea, the vibrations create waves in the cochlear fluid, causing the basilar membrane to move. The movement of the basilar membrane stimulates tiny hair cells located on it. These hair cells convert mechanical vibrations into electrical signals through a process called transduction. Different frequencies of sound stimulate different parts of the basilar membrane, allowing the ear to distinguish between various pitches. The hair cells release neurotransmitters in response to their movement, which generates electrical impulses in the auditory nerve. These electrical signals travel along the auditory nerve to the brain. The auditory signals reach the auditory cortex in the brain, where they are processed and interpreted as recognizable sounds, such as speech, music, or noise.
Some “Hard Facts” to better understand the dimensions of sound waves:
- The typical frequency range of human hearing is from ~20 Hz to ~20.000 Hz (20 kHz). This range can vary with age and exposure to loud sounds.
- The frequency of humans speaking typically falls within the range of ~300 Hz to ~3.400 Hz (3.4 kHz).
- Human ears are most sensitive to frequencies between 2,000 Hz and 5,000 Hz.
- The quietest sound that the average human ear can hear is around 0 dB SPL (sound pressure level), equivalent to 20 micropascals.
- The loudest sound that the average human ear can tolerate without pain is around 120-130 dB SPL. Sounds above this level can cause immediate hearing damage.
- The range between the threshold of hearing and the threshold of pain is known as the dynamic range of human hearing, which is approximately 120 dB.
How Digital Audio Works
Now, that we got a rudimentary understanding of sound waves in the analog world work, let’s continue with sound waves in a world of zeroes and ones.
When we talk about audio in a digital context, we’re referring to sound that’s been captured, processed, and played back using computers.
Audio-Input and Sampling
Sampling to computers is what hearing is to humans. Sampling is the process of converting analog sound waves into digital data that a computer can process. This is done by taking regular measurements of the amplitude of the sound wave at fixed intervals. The rate at which these samples are taken is called the sampling rate and is measured in samples per second (Hz). Common sampling rates include 44.1 kHz (CD quality) and 48 kHz (professional audio).

Each lollipop on the sine wave represents a single discrete sample/measurmeent. The first oscillation has a higher sample rate, the second oscillation has a lower sample rate for demonstration purposes only. Typically, the sample rate is constant, and more than double of the highest frequency humans can hear.
Nyquist-Shannon
The Nyquist-Shannon Sampling Theorem provides a criterion for determining the minimum sampling rate that allows a continuous signal to be perfectly reconstructed from its samples. A continuous-time signal that has been bandlimited to a maximum frequency fmax (meaning it contains no frequency components higher than fmax) can be completely and perfectly reconstructed from its samples if the sampling rate fs is greater than twice the maximum frequency of the signal.
Mathematically, this can be expressed as: fs > 2 * fmax
This nicely explains why common sampling rate are typically a little bit more than double of the human hearing range (e.g. 44.1 kHz for CD quality).
Quantization
In the analog world, signals have infinite precision. For example, if you zoom in on a sine wave, you can always find more detail — the waveform continues to be smooth and precise no matter how close you zoom in. However, in the digital world, precision is limited. To understand this limitation, consider the question: “How many numbers can you represent between 0 and 1?” If you use 0.1 as the smallest possible increment value, you can only represent 10 discrete values between 0 and 1. If you refine the smallest increment to 0.01, you get 100 values between 0 and 1. In the analog realm, there’s no smallest possible increment; values can be infinitely precise. But in digital systems, precision is constrained by the number of bits used to represent the signal. Digital audio uses a fixed number of bits to encode each sample of sound. For instance, with 16-bit audio, there are 65,536 discrete levels available to represent the amplitude of each sample. This means that the smallest difference between two levels, or the smallest possible increment, is approximately 0.000030518 for 16-bit audio. Professional audio will typicall utilize 24-bit. Everything higher than that is usually bogus. Bogus where only audiophiles will hear a difference.
The process of approximating each sample’s amplitude to the nearest value within these discrete levels is known as quantization. The number of discrete levels depends on the bit depth of the audio. For example:
- 16-bit audio provides 65.536 possible amplitude values.
- 24-bit audio offers 16.777.216 possible amplitude values.
Quantization is essential because it allows us to represent analog signals with a finite number of discrete values, making digital storage and processing feasible, even though we sacrifice some level of precision compared to the analog world. Once again, for all the audiophiles reading this: 24-bit resolution is enough! No, you don’t hear the difference between analog signals and 24-bit digital signals.
Storing Digital Audio signals?
With an understanding of sampling and quantization, we can continue to explore how digital audio can be stored. For illustrative purposes, let’s consider designing a basic audio format to store digital audio, using the simplicity of the CSV (Comma-Separated Values) format as our foundation. Although this proposed format would be inefficient compared to established audio formats like MP3, WAV, or FLAC, it serves as a useful exercise in understanding the principles behind audio file storage. CSV files are a well-known format (for software developers as well as spreadsheet power users), used to store tabular data in an easily readable manner. CSV files consist of rows separated by newlines and columns separated by commas, making them an ideal starting point for conceptualizing audio storage. The key here is to recognize that a sampled audio signal can be represented like table with data for a line-chart in a spreadsheet, where each row corresponds to a discrete sample in time.
Let’s define a CSV-based audio format with the following structure:
- Sample Index: Each row represents a discrete sample point. For example, in the case of a sine wave, each row corresponds to a specific point along the waveform. Typically the sample index is just a self-incrementing number.
- Quantized Value: The second column contains the quantized amplitude value for each sample.
- for simplicity sake, we assume that the sample rate is 44.1 kHz (this information is needed for later playback) and the bit depth is statically set to 16 bit.
a simple CSV file could like this:
Sample Index, Quantized Value
1, 0.32767
2, 0.32780
3, 0.32809
4, 0.32853
...While CSV is of course not a practical choice for real-world audio storage due to its inefficiency and lack of support for metadata, compression, multiple channels, and other critical features, this format helps to illustrate how digital audio data can be organized and stored. Real-world formats like MP3, WAV, and FLAC utilize more sophisticated techniques to handle audio data more efficiently, like
- applying Compression to reduce the file size (in the best case: while maintaining audio quality)
- Metadata, for storing additional information about the audio file, such as title, artist, and duration, sample rate, bit-depth
- Error Correction for ensuring data integrity during storage and playback.
- as well as support for multiple channels (e.g. for stereo signals or 5.1/7.1 channels for cinematic sound systems)
Mono and Stereo
Mono (short for monaural) refers to audio that is recorded and played back through a single channel. In a mono audio setup, all sounds are combined into a single channel, and this single channel is then played through one or more speakers or headphones. The primary advantage of mono audio is its simplicity and the uniformity it provides — sound is uniformly distributed regardless of how many speakers are used. This makes mono suitable for applications where spatial sound is not crucial, such as telephone conversations. Even audio on bigger venues is typical mono.
On the other hand, stereo (short for stereophonic) involves two audio channels: left and right. Stereo recording captures sound from two distinct channels, creating a sense of spatial separation between sounds. This allows for a more immersive listening experience because different sounds can be directed to different speakers or headphones. For instance, in a stereo mix, you might hear a guitar predominantly through the left speaker and a vocal through the right speaker. This spatial separation mimics the way humans (with typically only 2 ears) naturally hear sounds in real life, making stereo effective for music, movies, and other applications where a realistic sound field enhances the experience.
Audio-Output
We’ve learned a lot about sound waves, and how sound waves can be captured and stored. Now it’s time to move forward and think about how digitally stored audio is played back. As discussed in the previous section, digital audio data is typically stored as a sequence of discrete samples that represent the amplitude of a sound wave at various points. This data is then streamed to your computers sound card. A DAC (abbreviation for Digital-To-Analog) converter converts these digital values into a continuous analog signal. This conversion process typically involves 2 steps. First, the digital samples are mapped to discrete voltage levels. In case your sound card outputs line-level, the highest possible digital representable value would map to 0.447V (447 mV). To smooth out the discrete steps and reconstruct a continuous waveform, the DAC uses a low-pass filter. This filter removes high-frequency artifacts (often referred to as “sampling noise”) that result from the discrete nature of the digital data. The Low Pass Filter is typically filtering out every frequency above ~22 kHz. Finally, the filtered analog signal is sent to the output stage, which then drives the speakers or headphones.
The Role of a Sound Card / Audio Interface
A sound card handles the input and output of audio signals, converting between analog and digital forms. Sound cards typically include ADCs for recording, DACs for playback, and additional circuitry for audio processing (such as amplification, filtering, noise-removal, etc. …). In a nutshell sound cards act as the ears and the mouth of your computer. It handles all the inputs, like microphones, line-inputs and makes it consumable from software running on your computer. And then it also handles output of digital audio to analog systems such as your speakers and your headphones.
The most basic sound card consists out of the following components:
- ADCs (Analog-to-Digital Converters): Converts analog signals from microphones or other input devices into digital data.
- DACs (Digital-to-Analog Converters): Converts digital audio data into analog signals for playback through speakers or headphones.
- Amplifiers: Boosts the audio signal to a level that can drive speakers or headphones.
What makes a good Sound Card / Audio Interface?
Often times I get asked what audio interface is a good audio interface. I usually don’t want to recommend a particular brand, but explain people what they should look for when comparing audio interfaces to find one that suits their needs. Here’s a short and opinionated set of aspects you should look out for.
- Signal-to-Noise Ratio (SNR): A high SNR indicates that the sound card produces clear audio with minimal background noise. Look for a sound card with a high SNR, typically 100 dB or higher.
- Total Harmonic Distortion (THD): Low THD means that the sound card introduces minimal distortion to the audio signal. Good sound cards often have THD ratings below 0.01%.
- Dynamic Range: A wide dynamic range allows the sound card to accurately reproduce both very quiet and very loud sounds without distortion or noise.
- Sampling Rate: A higher sampling rate allows for more accurate representation of audio. Common high-quality sound cards support rates up to 192 kHz or higher.
- Bit Depth: A higher bit depth enables better resolution of audio details. Good sound cards support 24-bit depth, providing a broader range of amplitudes and finer detail.
- Low Latency: Good sound cards have low latency, which is essential for real-time applications like gaming, live recording, and professional audio production. Latency is the delay between input and output, and lower latency ensures more immediate audio responses.
The Stairstep Fallacy
Source: Invidious on yt.rtrace.io provided by ruffy
The Linux Audio Stack
Now that we’ve covered the basics, let’s have a look at how Linux manages audio. The Linux audio system utilizes a modular and layered architecture to handle audio processing, which provides both abstraction and flexibility. Layering in Linux audio allows for a structured approach to audio management. By separating concerns into different layers, the system abstracts the complexities of lower-level operations, such as direct hardware interactions. This separation means that user-space applications do not need to deal with the specifics of hardware configurations, streamlining development and improving compatibility. Modularity complements the idea of layering by allowing individual components to be swapped or reconfigured without disrupting other layers in the system. This means that different layers or components can be replaced or updated as needed. For example, if you plug in a headset, the system can dynamically switch from speaker output to headset output thanks to its modular design. Similarly, if you change your sound card or audio driver, the modular system can adapt without requiring much reconfiguration.
ALSA (Advanced Linux Sound Architecture)
Let’s start with the foundation of all Linux systems when it comes to audio. ALSA is the core layer of the Linux audio stack. It provides low-level audio hardware control, including drivers for sound cards and basic audio functionality. ALSA provides a standardized interface for audio hardware, allowing applications to interact with sound cards and other audio devices without needing to know the specifics of the hardware. It includes a set of drivers for different types of sound cards and audio interfaces. These drivers translate the high-level audio commands from applications into low-level instructions understood by the hardware.
ALSA operates in the kernel space, meaning it interacts directly with the Linux kernel. This position allows it to manage hardware resources and perform low-level audio operations efficiently. To allow the user space from profiting from ALSA too, ALSA provides libraries and tools in user space, such as libasound (the ALSA library), which applications can use to interface with the ALSA parts in the kernel space. This library offers functions for audio playback, recording, and control.
ALSA supports multi-channel audio, enabling more advanced configurations like 5.1 or 7.1 surround sound. Additionally, it is designed to offer low-latency audio, which is essential for real-time applications like music production. Further, ALSA includes a mixer interface that allows users to control audio levels and settings, such as adjusting volume or muting channels.
JACK
The Jack Audio Connection Kit - better known as JACK - is a professional-grade audio server designed for UNIX-oid operating systems, including Linux. It is tailored for real-time, low-latency audio processing and is widely used in professional audio production. JACK is designed to provide low-latency, real-time audio. This is essential for applications where timing and synchronization are critical, such as live music performance, recording, and audio production. It allows multiple audio applications to connect and communicate with each other. This means that the output of one application can be flexibly routed to the input of another, enabling complex audio processing chains.
JACK excels in delivering minimal latency. This ensures that audio signals are processed and transmitted with minimal delay, maintaining synchronization and responsiveness across multiple tracks/applications outputting audio at the same time. It offers sample-accurate synchronization between audio streams, ensuring precise timing and phase alignment across different audio applications and devices. JACK uses a client-server model, where the JACK server manages audio data and clients (like your desktop applications) connect to it for audio processing. This modular approach enables flexibility and scalability in audio setups. JACK includes transport control features that allow users to synchronize playback and recording across multiple applications, making it easier to manage more complex audio projects. JACK builds on top of ALSA and requires ALSA to be installed and configured correctly.
PulseAudio
PulseAudio is a sound server for Linux and other UNIX-oid operating systems that sits on top of the lower-level ALSA. It provides a higher-level interface for audio management, offering additional features beyond those available through ALSA. PulseAudio acts as an intermediary between applications and the underlying sound hardware. It handles audio streams, mixing, and routing, allowing multiple applications to produce sound simultaneously and manage their audio independently. One of PulseAudio’s key features is its ability to stream audio over a network. This allows users to play audio from one machine on another machine or device connected to the same network.
PulseAudio enables the mixing of multiple audio streams into a single output. This means you can listen to music while receiving notifications from other applications, all mixed seamlessly into your speakers or headphones. Additionally, it allows for independent volume control of each application. This means you can adjust the volume of your music player separately from your web browser or other applications. PulseAudio supports various audio effects and processing features, such as equalization, sound enhancements, and echo cancellation. Further, it manages audio devices and allows easy switching between them. For instance, you can switch audio output from speakers to headphones or to an external Bluetooth device without disrupting playback.
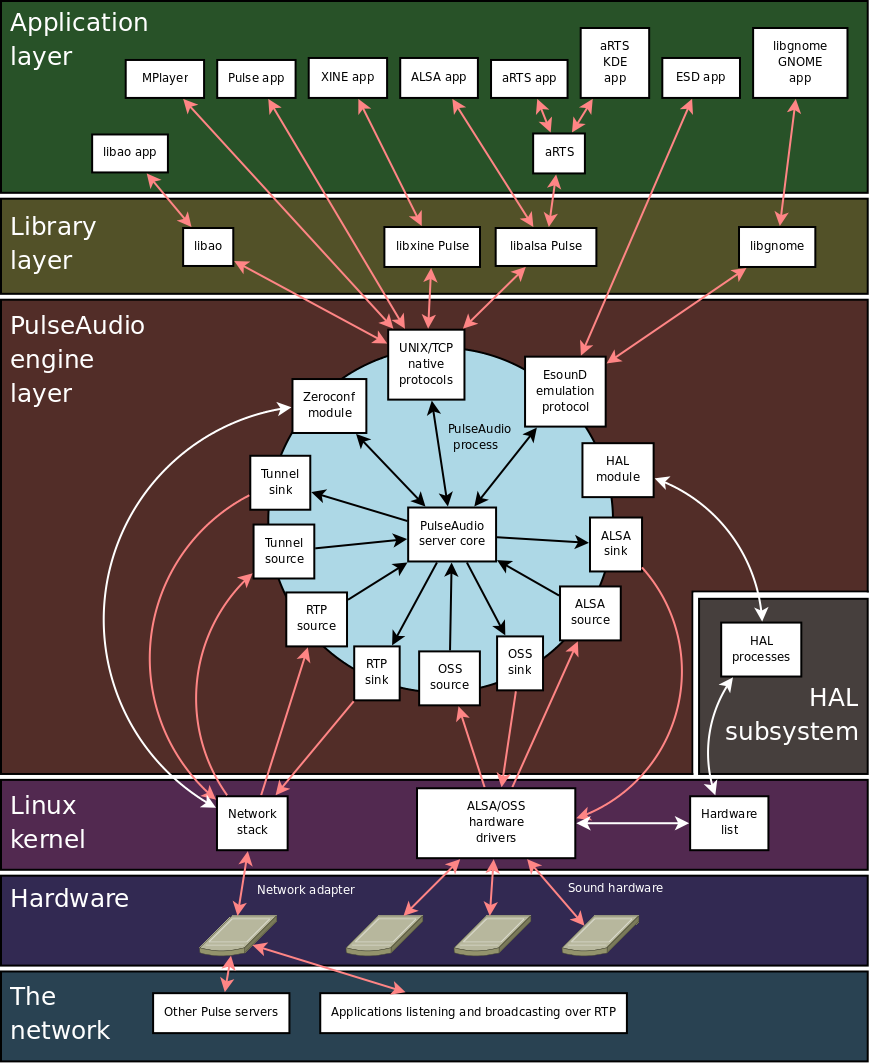
PulseAudio provides a more intuitive and user-friendly way to manage audio compared to working directly with ALSA. Its ability to handle various audio sources and outputs simultaneously, along with network capabilities, makes it versatile for different audio needs and setups. By providing advanced features such as audio mixing, device switching, and network streaming, PulseAudio contributes to a richer and more flexible audio experience on Linux systems - particularly the Linux Desktop. While it’s a little bit of a meme, PulseAudio made “the year of the Linux desktop” a lot more likely.
PipeWire
PipeWire is a modern multimedia framework designed for Linux systems that aims to unify and enhance the handling of both audio and video streams. Developed as a replacement for both PulseAudio and JACK, PipeWire provides a flexible and efficient infrastructure for managing complex multimedia tasks. PipeWire combines the capabilities of audio servers like PulseAudio and low-latency audio servers like JACK into a single framework. It also supports video processing and capture, making it a comprehensive solution for managing both audio and video streams. Like JACK, PipeWire offers low-latency audio processing, which is crucial for professional audio applications such as live music production and sound design.
PipeWire is designed to be highly flexible, accommodating various use cases ranging from consumer audio and video to professional audio production and due to its video capabilities also video conferencing. It provides a unified API that can handle both audio and video streams, simplifying development and integration for applications that need to process multimedia content. Further, PipeWire is engineered from the ground up to deliver low-latency audio and real-time performance, making it suitable for high-performance audio tasks and complex multimedia workflows. Finally, PipeWire includes features for improved security and sandboxing, allowing applications to access only the resources they need and protecting against potential security vulnerabilities.
By combining audio and video management into a single framework, PipeWire provides a more integrated and cohesive approach to handling multimedia content. Its design incorporates modern requirements and use cases, including enhanced security, better real-time performance, and support for a wide range of multimedia applications. PipeWire also offers compatibility with existing audio and video servers, easing the transition from older systems and allowing a more gradual adoption. To give an example, even if one of your applications is built to use PulseAudio, PipeWire supports a PulseAudio compatible input API, so that an application does not have to care if it’s PulseAudio or PipeWire. A similar input API exists also for JACK - PipeWire will emulate the Sound Server API of JACK. Unlike PulseAudio and JACK, PipeWire does not require ALSA user-space libraries at all. Often times user space ALSA applications are re-routed to PipeWire for sound output and input
So what is it a sound server does?
Mixing multiple input streams
Briefly summarized, a sound server acts as an intermediary that takes multiple audio input streams with varying sample rates and bit depths, mixes them into a single output signal, and sends it to the sound card. For example, imagine one application generating a sine wave and another producing a rectangular wave. In today’s world, it would be unimaginable not to be able to watch a video while simultaneously receiving notification sounds from your messenger (or more generally to receive audio from multiple input sources). This is where the sound server implementations such as PipeWire, JACK and PulseAudio come in — a sound server combines the two (or more) input signals into one output signal and outputs it to the sound card. The sound server achieves this by summing each sample of the input signals, effectively merging multiple inputs into a single output. The operation performed is sample-wise addition. In case a faster-sampled signal needs to mixed with a lower-sampled signal, the audio server will also have to interpolate the values for the signal with the lower sample rate. All this is happening in real time with little to no latency introduced (depending on the buffer size of the mixer buffer).
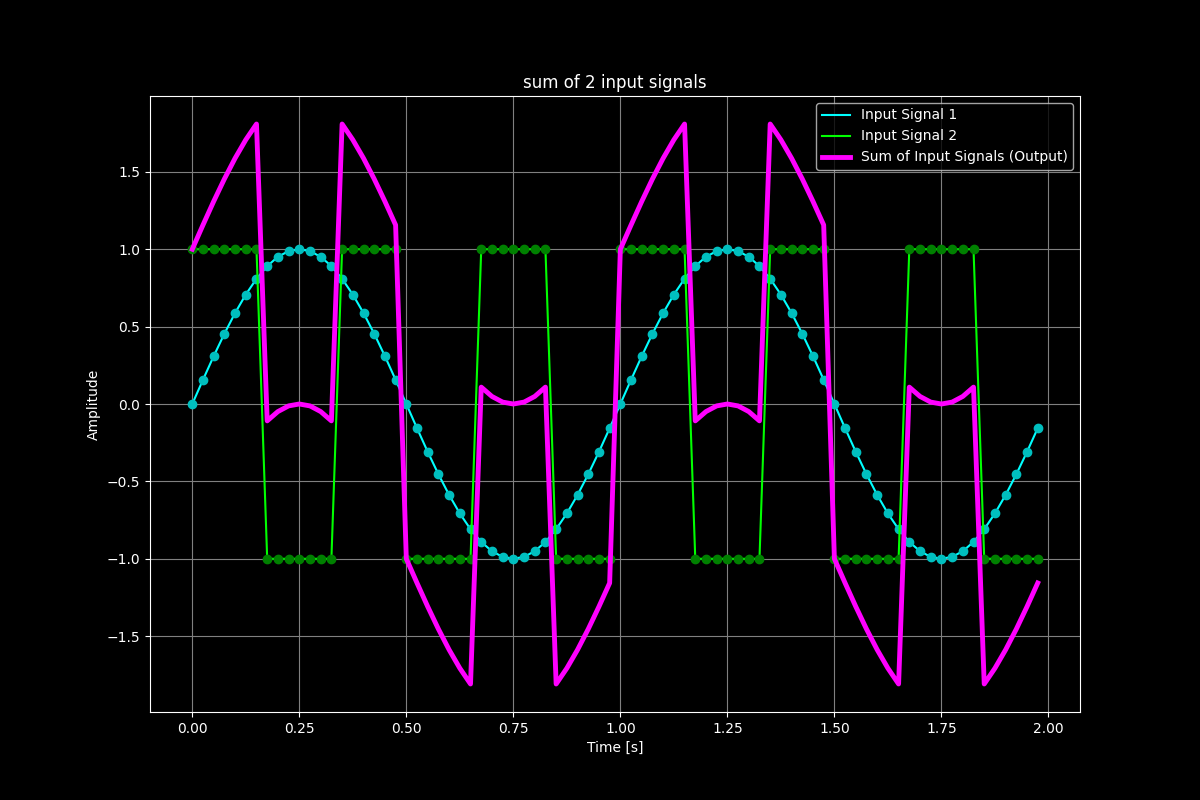
Multiple Output Streams/Mixes
If you own a laptop, there’s high chance you have 2 (or more) audio output devices. One Headphone output if you connect your headphones to the audio output jack. And one for the built-in speakers in your laptop. A sound server can also output audio to multiple outputs at the same time. Let’s say you prefer listening to music through your headphones, but friend is with youoand you’d like to show them a cool song you enjoy. So you decide to activate output on both devices at the same time.
Volume Control per input stream
Typically each input stream comes from different applications on your Linux Desktop. And sometimes you’d like to individually control volume for each of your applications. Let’s say you’re watching a movie and you’d like to mute all messengers in the meanwhile. You can configure the sound server to reduce/mute the volume of the corresponding input streams of your messengers.
Virtual Outputs
Not every signal needs to be routed to an actual output. Think about your microphone. Most of the time the microphone is not played back to speakers/headphones, yet the input stream is provided to applications such as your favorite VOIP/conferencing tool. The concept of virtual outputs allows you to create an arbitrary number of output streams that applications can consume.
Sound effects for streams
A sound server enables you to apply various effects to individual input streams or output streams using effect plugins. These plugins, available in formats such as LADSPA, CLAP, VST2, VST3, AU, and RTAS, allow you to integrate software effects into your audio routing chain.
Example: Using a Compressor
One practical example of an effect plugin is a compressor. If you often find yourself adjusting the volume while watching movies—turning it down during loud action scenes and back up for quieter dialogue—a compressor can help. By adding a compressor to the input stream of your media player or browser, you can reduce the volume of the loud parts without affecting the quieter sections. Most compressors include a make-up gain feature to increase the overall volume after compression, ensuring a balanced listening experience.
Example: Adding Reverb
Another use case is enhancing your microphone input with a bright reverb effect, making it sound as though you’re speaking in a large room. This can add a sense of space and presence to your voice.
Example: Applying an Equalizer
You might also want to use an equalizer to adjust your output stream. For instance, if your speakers produce a muddy bass around 200Hz, you can use an equalizer to reduce the gain in that frequency range, resulting in clearer sound.
Example: Denoising
If your microphone has a lot of background noise, you can apply a denoising effect to clean up the signal before it reaches your VOIP tool. This ensures that your voice comes through clearly during calls.
Combining Multiple Effects
For more advanced setups, you can combine multiple effects like reverbs, delays, compressors, and equalizers into your audio chain. Whether you need simple adjustments or complex processing, a robust sound server provides the flexibility and control you need.
The modular and layered design of the Linux audio stack, combined with the wide array of available plugins, allows you to customize your audio experience to suit your specific needs. If you’re looking to enhance your media playback, improve your microphone input, or create a unique sound environment, the Linux audio stack has the tools to make it happen.
Providing an API for application developers
Another important aspect of a sound server is to provide a convenient API for application developers to consume. The following Python script demonstrates how the ALSA API can be used to playback a *.wav file.
import audioop
import alsaaudio
# Initialize ALSA-Audio-Output
audio_output = alsaaudio.PCM(alsaaudio.PCM_PLAYBACK)
audio_output.setchannels(1) # mono
audio_output.setrate(44100) # 44.1 kHz
audio_output.setformat(alsaaudio.PCM_FORMAT_S32_LE)
with open('example-audio-file.wav', 'rb') as wav_file:
try:
audio_output.setperiodsize(160)
data = wav_file.read(320)
while data:
# Write read bits of audio file to sound card
audio_output.write(data)
data = wav_file.read(320)
except Exception as exc:
print(exc)
Which sound server is better for me?
To help you understand which sound server suits your needs the best, I tried to collect some use-cases and rated the corresponding implementations capability to fulfill these use-cases. Note, that the rating might be a very opinionated rating, and you might disagree. Let’s discuss in the comment section below!
| Use Case | JACK | PulseAudio | PipeWire |
|---|---|---|---|
| Professional Audio Production | ★★★★★ | ★★★ | ★★★★☆ |
| Real-Time Audio Processing | ★★★★★ | ★★ | ★★★★☆ |
| Low-Latency Audio | ★★★★★ | ★★ | ★★★★☆ |
| Live Music Performance | ★★★★★ | ★★ | ★★★★☆ |
| General Desktop Audio | ★★ | ★★★★★ | ★★★★★ |
| Network Audio Streaming | ★★★★ | ★★★ | ★★★★☆ |
| Bluetooth Audio Devices | ★★ | ★★★★ | ★★★★★ |
| Video Conferencing | - | - | ★★★★★ |
| Screen Recording | - | - | ★★★★★ |
| Audio Routing Between Apps | ★★★★★ | ★★★ | ★★★★★ |
| Multi-User Audio Management | ★★★ | ★★★★ | ★★★★★ |
| Security and Sandboxing | ★★★ | ★★★ | ★★★★★ |
| Ease of Configuration | ★★ | ★★★★★ | ★★★★☆ |
| Compatibility with Consumer Apps | ★ | ★★★★★ | ★★★★★ |
| Handling MIDI | ★★★★★ | ★★★ (requires FluidSynth) | ★★★★☆ |
| High-Performance Gaming Audio | ★★ | ★★★★ | ★★★★☆ |
| Podcasting and Broadcasting | ★★★★☆ | ★★★★ | ★★★★★ |
| Remote Audio Processing | ★★★★☆ | ★★★ | ★★★★☆ |
| Developing Audio Applications | ★★★★★ | ★★★ | ★★★★★ |
| Effect Support (LADSPA, etc. …) | ★★★★☆ | ★★★ | ★★★★★ |
PipeWire is a versatile and powerful option that integrates the best features of both JACK and PulseAudio, making it suitable for a wide range of use cases from general desktop audio to professional audio - and thanks to it’s video capabilities - also video production. JACK remains the best choice for professional audio work requiring the lowest latency and real-time performance. PulseAudio continues to be the benchmark in general desktop and consumer audio applications, with ease of use and broad compatibility.
The Linux distribution you’re currently on likely already uses either PipeWire or PulseAudio. RHEL-based distributions are on PipeWire already (e.g. Fedora), most Debian-based are on PulseAudio, but PipeWire is installable through your package manager. If you’re satisfied with your current audio stack, there’s no need to change it. However, if you seek lower-latency capabilities, or are unhappy with the stability of your current sound server, consider upgrading to PipeWire. Generally speaking I’d not recommend transitioning to JACK unless you’re already familiar with its configuration and setup. PipeWire will eventually completely replace PulseAudio and JACK, as from an architectural and technical view it is a lot more capable.
Comments 💬